Avoiding SQL Server plan cache pollution due to unparameterized Contains queries generated by Entity Framework 6
In this post I will describe an approach to solving an issue with Entity Framework 6 and queries using Contains I have previously blogged about.
The SQL Server plan cache is a limited resource, and if SQL statements are not parameterized, you can end up with so many plans in the query cache, that on a busy system the database engine will spend all it's time evicting plans from the cache, instead of delivering query results!
I proposed a solution for EF Core using STRING_SPLIT in my blog post here
This issue also affects the 'classic' Entity Framework 6, and a blog post reader asked if it was possible to implement a similar solution for Entity Framework 6 - and yes, it is possible :-) !
This solution takes advantage of a library created by a former EF team member.
To get started, add this NuGet package to your project:
Install-Package EntityFramework.CodeFirstStoreFunctions -Version 1.2.0
Sample code
Let's see how to put the parts together.
First add a class to hold the return value from the STRING_SPLIT function.
Notice that you must use the [Key] attribute to fake a key for the class, otherwise Entity Framework 6 complains.
public class StringSplitResult
{
[Key]
public string Value { get; set; }
}
Add this to your OnModelCreating method in your DbContext:
using CodeFirstStoreFunctions;
...
modelBuilder.Conventions.Add(new FunctionsConvention<NorthwindContext>("dbo"));
Then extend your DbContext with the following code.
public partial class NorthwindContext
{
public DbSet<StringSplitResult> StringSplitResults { get; set; }
[DbFunction(nameof(NorthwindContext), nameof(String_split))]
[DbFunctionDetails(IsBuiltIn = true)]
public IQueryable<StringSplitResult> String_split(string source, string separator)
{
var sourceParameter = new ObjectParameter("Source", source);
var separatorParameter = new ObjectParameter("Separator", separator);
return ((IObjectContextAdapter)this).ObjectContext
.CreateQuery<StringSplitResult>(
string.Format("[{0}].{1}", GetType().Name, "STRING_SPLIT(@Source, @Separator)"),
sourceParameter, separatorParameter);
}
}
First, a DbSet for the StringSplitResult class is added to the DbContext.
Then the mapping for the built-in STRING_SPLIT Table Valued Function (TVF) is added, using the EF 6 DbFunction attribute, combined with DbFunctionDetails from the third party EntityFramework.CodeFirstStoreFunctions library.
Let's test the code and inspect the generated SQL!
using (var db = new NorthwindContext())
{
db.Database.Log = Console.WriteLine;
var list = new[] { "ALFKI", "BERGS", "VAFFE" };
var result1 = db.Orders
.Where(s => list.Contains(s.CustomerID))
.Select(o => new { o.OrderDate, o.CustomerID })
.ToList();
var joined = string.Join(",", list);
var result2 = db.Orders
.Where(s => db.String_split(joined, ",")
.Any(l => l.Value == s.CustomerID))
.Select(o => new { o.OrderDate, o.CustomerID })
.ToList();
}
The first query that uses plain Contains generates this non-parameterized (hard-coded) query, which will cause plan cache pollution:
SELECT
1 AS [C1],
[Extent1].[OrderDate] AS [OrderDate],
[Extent1].[CustomerID] AS [CustomerID]
FROM [dbo].[Orders] AS [Extent1]
WHERE ([Extent1].[CustomerID] IN (N'ALFKI', N'BERGS', N'VAFFE')) AND ([Extent1].[CustomerID] IS NOT NULL)
The second query generates the following, properly parameterized SQL. (If someone can come up with a more elegant approach to calling the String_split function, please come forward!)
SELECT
1 AS [C1],
[Extent1].[OrderDate] AS [OrderDate],
[Extent1].[CustomerID] AS [CustomerID]
FROM [dbo].[Orders] AS [Extent1]
WHERE EXISTS (SELECT
1 AS [C1]
FROM STRING_SPLIT(@p__linq__0, N',') AS [Extent2]
WHERE ([Extent2].[Value] = [Extent1].[CustomerID]) OR (([Extent2].[Value] IS NULL) AND ([Extent1].[CustomerID] IS NULL))
)
-- p__linq__0: 'ALFKI,BERGS,VAFFE' (Type = String, Size = 4000)
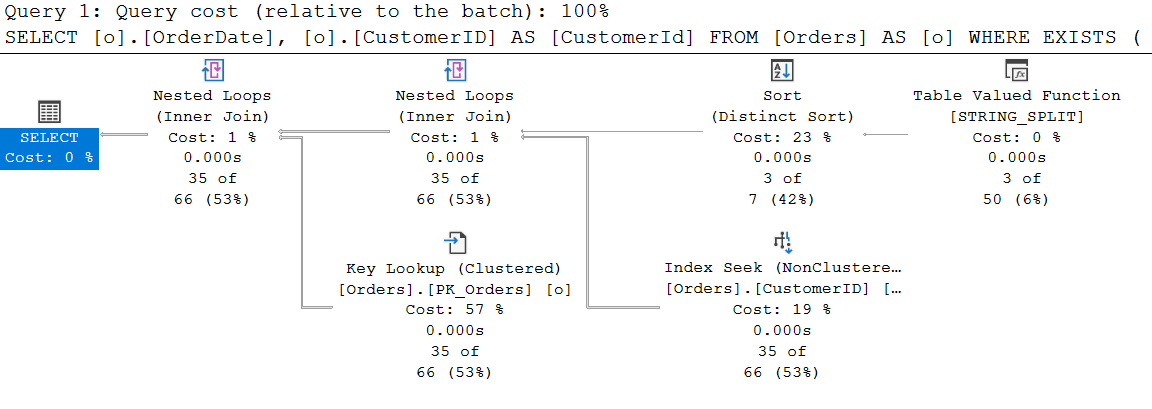
And as we can see from the query plan, SQL Server is able to use an existing index on CustomerID:
Thanks to stevendarby, smitpatel and moozzyk for inspiration to this solution!
Happy coding!